arXiv Paper - Unveiling Super Experts in Mixture-of-Experts Large Language Models - 揭示MoE LLM中的超级专家:作用机制与性能影响

Unveiling Super Experts in Mixture-of-Experts Large Language Models
Executive Summary: Unveiling the "Critical Few" in MoE LLMs
This article's core finding reveals the existence of an extremely small, yet critically important, subset of "Super Experts" within MoE LLM architectures. These "Super Experts", typically accounting for far less than 0.05% of the total, exert a decisive influence on the model's overall performance, particularly its mathematical reasoning capabilities.
An MoE LLM can be conceptualized as a large consulting firm with numerous specialized departments (i.e., "experts"). When a complex query is posed, an internal "router" mechanism intelligently selects a few of the most relevant departments (experts) to address it, rather than involving all departments. This strategy aims to enhance efficiency and the ability to tackle intricate problems.
In this analogy, "Super Experts" are akin to the select few top-tier specialists within the firm who possess a "Midas touch." While they may not be frequently called upon, their output, once engaged, generates an exceptionally powerful "signal." This signal propagates like ripples, ultimately influencing the firm's overall decisions (model output). Should these "Super Experts" be removed, the firm's core operational capabilities (model performance) would suffer a devastating blow.
MoE LLM Overview and Research Background: Why Focus on "Experts"?
First, let's briefly understand MoE LLMs. Traditional LLMs process information like a vast brain, with all neurons participating in computations to some extent. MoE LLMs, however, adopt a "divide and conquer" strategy: they replace the model's internal "FFN" (which can be understood as the "thinking units" that process information) with individual "experts" (also FFNs). When the model needs to process a piece of text or a question, a mechanism called a "router" intelligently selects a few of the most suitable "experts" to participate in the computation. This "sparse activation" approach allows for significantly enhanced learning capabilities by keeping inference costs (the resources actually involved in computation) relatively low, despite the massive total parameter count.
For instance, well-known advanced models such as DeepSeek and Qwen adopt this architecture.
Despite their power, the immense total parameter count of MoE LLMs presents challenges for deployment and inference. Consequently, researchers have been exploring methods for model "compression" – reducing model size without significant performance loss, making them easier to deploy.
Previous model compression techniques, such as pruning (removing unimportant parts), quantization (reducing data precision), or merging (combining multiple smaller parts), largely relied on empirical judgments of which "experts" were less critical. However, this article posits that these methods might lack a deeper understanding of expert importance. This research aims to fill that gap: Does a subset of experts exist within MoE LLMs that plays a critical role during forward inference?
Discovery and Identification of SEs: A Needle in a Haystack
Researchers conducted extensive experimental analyses on various mainstream open-source MoE LLMs (e.g., DeepSeek series, Qwen3 series, Mixtral), leading to the first discovery of "Super Experts".
Preliminary Evidence: The Striking Results of Pruning Experiments
A very intuitive example is observed in the Qwen3-30B-A3B model, which comprises approximately 6,000 experts. Research revealed that pruning merely 3 experts was sufficient to cause a substantial performance degradation, whereas randomly pruning hundreds of other experts had virtually no impact on performance.
Consider the following chart: Qwen3-30B-A3B Model Expert Pruning Analysis Chart
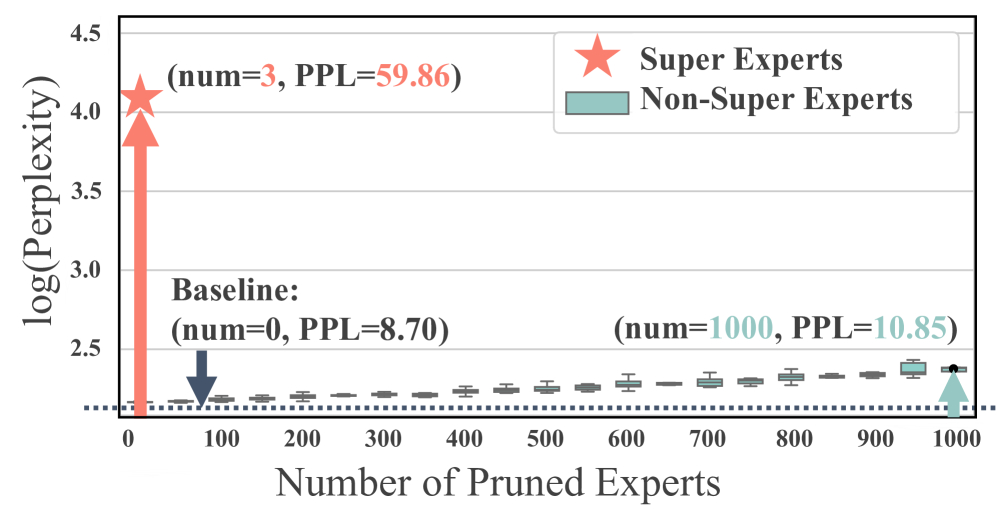
The chart illustrates that the baseline model (unpruned) exhibited a Perplexity (PPL) of 8.70. Perplexity (PPL) is a metric measuring a language model's "uncertainty" in predicting the next word; a lower PPL indicates more accurate model predictions. Upon pruning 3 "Super Experts", the PPL sharply deteriorated from 8.70 to 59.86, indicating a catastrophic impact on the model's comprehension and generation capabilities. Even randomly pruning 1,000 non-"Super Experts" resulted in only a marginal increase in PPL to 10.85, demonstrating a negligible effect. This strongly suggests the extraordinary nature of these 3 experts.
Mechanism Origin: Inducing "Massive Activations"
So, why are these "Super Experts" so crucial? Research indicates that their importance stems from their ability to induce a phenomenon known as "Massive Activations".
- What are "Massive Activations"? Imagine that during an LLM's information processing, information flows like electrical currents between "neurons." The output intensity of each "neuron" is its "activation value." "Massive Activations" refer to the occurrence of unusually high activation values (potentially tens of thousands of times higher than normal activations) at certain critical junctures within the model, appearing as "outliers." This can be understood as, in a company's information flow, a critical report or decision whose importance is greatly "amplified," generating an extremely strong "impact signal" that far exceeds ordinary information.
"Super Experts" are the Direct Source of "Massive Activations" Research has found that these "Massive Activations" do not appear randomly; rather, they are induced by a very small number of specific "Super Experts". When these "Super Experts" produce output in their "output transformation layer" (the down_proj layer, which can be understood as the expert's final "output port" after processing information), extreme "activation outliers" occasionally emerge. These extreme activation values accumulate into the next layer's input via "Residual Connection" (akin to a "carbon copy" mechanism in information transfer, where original information bypasses some intermediate processing steps and is directly added to the input of the next layer). More importantly, these extreme values are continuously amplified through an "activation amplification chain" mechanism as they are passed through the model's layers, ultimately forming stable and significant "Massive Activations" in the deeper layers of the model.For example, in the Qwen3-30B-A3B model, expert 68 in Layer 1, expert 92 in Layer 2, and expert 82 in Layer 3 collectively form an "activation amplification chain." The "Super Experts" in Layer 1 generate an initial "signal peak," which is transmitted to Layer 2, further amplified by the "Super Experts" in Layer 2, and then propagated to Layer 3, where it is amplified again by the "Super Experts" in Layer 3, ultimately forming a continuous "Massive Activations" flow within the model.Super Experts Mechanism in Qwen3-30B-A3B

This diagram vividly illustrates the "activation amplification chain": Super Experts (E68) in Layer 1 generate a high activation value, which is passed to Layer 2, further amplified by Super Experts (E92) in Layer 2, and then passed to Layer 3, where it is amplified again by Super Experts (E82) in Layer 3, ultimately forming a sustained "Massive Activations" flow within the model.The research validated this point through pruning experiments: when a "Super Experts" in a certain layer is pruned, its influence on "Massive Activations" in that layer disappears; if all "Super Experts" are pruned, the originally significant "Massive Activations" phenomenon completely vanishes. This irrefutably proves that "Super Experts" are the direct source of "Massive Activations" within the model.
Identification and Localization Methods: How to Pinpoint "Super Experts"?
Given that "Super Experts" influence "Massive Activations", researchers proposed a concise and effective identification method based on this characteristic. Simply put, they set several conditions: if an expert, in its down_proj output, generates an abnormally high activation magnitude (exceeding 99.5% of all experts' values, and also exceeding 1/10 of the maximum activation value), and it resides in a layer where "Massive Activations" form, then it is identified as a "Super Experts".
The researchers also developed an automated tool to quickly and accurately identify "Super Experts" in new models.
Distribution Characteristics: Rare, Stable, and Ubiquitous
The distribution of "Super Experts" exhibits several notable characteristics:
- Ubiquitous yet Scarce: "Super Experts" were found in all tested MoE LLMs, but their proportion typically accounts for far less than 0.05%. For example, in Qwen3-30B-A3B's 6,144 experts, only 3 are "Super Experts".
- Stable Distribution, Unaffected by Post-Training: This implies that "Super Experts" are formed during the model's pre-training phase, and their identity and position remain highly stable in subsequent fine-tuning or training, not easily changing.
- Consistent Distribution Across Data Domains: Regardless of whether the model processes Chinese text, code, or mathematical problems, the distribution of these "Super Experts" demonstrates astonishing stability. This suggests that their importance is not confined to specific tasks but universally impacts the model's fundamental capabilities.
Other Outlier Experts: Not All "High Activations" Are Equally Significant
It is worth noting that in the final layers of the model, some experts also produce extreme activation outliers, referred to as "Outlier Experts". However, the research indicates that these "Outlier Experts" differ from "Super Experts" in that they:
- Do not significantly impact model performance.
- Pruning them does not lead to abnormal model output.
- Their distribution varies with input data, unlike the stable nature of "Super Experts".
- They do not participate in the formation mechanism of "Massive Activations", as "Massive Activations" primarily occur in shallower layers of the model.
This is analogous to a company where, besides core technical backbone (the Super Experts), there might be employees who excel in specific minor tasks and have "shining moments" (the Outlier Experts), but their impact on the company's overall performance is not as substantial as that of the core backbone.
Analysis of SEs Significance: The Linchpin of Performance
After confirming the existence and mechanism of "Super Experts", the research further experimentally verified the severe consequences of pruning these "Super Experts", revealing their extreme importance to model performance.
Impact on Non-Reasoning Models: Universal Performance Degradation, Especially in Mathematical Tasks
The study tested model performance after pruning "Super Experts" across various non-reasoning tasks (e.g., common sense QA, reading comprehension).
- Significant Performance Decline: After pruning "Super Experts", the model's average accuracy universally decreased by 21.68% to 27.21%.
- Near Collapse in Mathematical Tasks: In mathematical tasks requiring a certain degree of logical reasoning, such as GSM8K, the performance decline was particularly severe, experiencing a massive drop of 52.71% to 74.51%.
- Negligible Impact of Random Pruning: In contrast, randomly pruning the same number of other experts had almost negligible impact on model performance. This again highlights the irreplaceable nature of "Super Experts".
Impact on Reasoning Models: Complete Loss of Reasoning Capability, "Short-Circuited" Chain-of-Thought
For models specifically designed for complex reasoning tasks (e.g., DeepSeek-R1 and the thinking mode of Qwen3-30B-A3B), the impact of pruning "Super Experts" was even more catastrophic.
- Complete Loss of Reasoning Capability: In highly challenging reasoning tasks such as AIME (American Invitational Mathematics Examination) and MATH-500, after pruning "Super Experts", the model's Pass@1 (one-shot pass rate) dropped directly to 0.00%. This implies that the model completely lost its ability to solve these complex reasoning problems. This is akin to a top mathematician who, if a very small number of critical "neurons" responsible for core logical operations in their brain were removed, would be completely unable to perform complex mathematical reasoning.
Model's Chain-of-Thought "Short-Circuited": A peculiar phenomenon observed when analyzing the test outputs for MATH-500 was that models with pruned "Super Experts" would fall into meaningless, mechanical repetition until reaching the maximum output length. For example, when asked to solve a mathematical problem, the original model could clearly analyze the problem and provide solution steps, whereas the model with pruned "Super Experts" would repeatedly say "that’s the. that’s the." or "But I need to reason step by step...", unable to produce any meaningful reasoning process. This indicates that "Super Experts" are crucial for the model to maintain its "Chain-of-Thought" and coherent reasoning capabilities.DeepSeek-R1 Output Results on MATH-500

The chart clearly demonstrates how the original model progressively analyzes the problem, while the model with pruned "Super Experts" falls into meaningless repetition.
Understanding the Impact of Pruning Super Experts on Attention Mechanisms: Crucial for Maintaining "Focus"
Beyond the direct impact on model performance, the research also delved into the influence of "Super Experts" on the model's internal "attention mechanisms."
Attention Sinks: The "Focal Points" of Information Processing
Within LLMs, a very important mechanism is called "MHSA". You can imagine this as the model, when reading a sentence, not just focusing on one word, but simultaneously understanding the relationship between each word and other words from multiple perspectives (multiple heads), thereby grasping the essence of the sentence.
Within this attention mechanism, a phenomenon called "Attention Sinks" exists. This means that certain special tokens (such as the first word of a sentence, or some punctuation marks) attract most of the model's "attention scores," acting like a "focal point" or "black hole" that draws in attention. Although these tokens themselves may not carry strong semantic meaning, their presence is crucial for maintaining a reasonable distribution of attention scores, helping the model better understand context and maintain information coherence.
Based on previous research findings that "Massive Activations" induce the formation of "Attention Sinks", combined with this paper's discovery that "Super Experts" trigger "Massive Activations", the authors propose an important causal chain hypothesis: Super Experts (Root Cause) → Massive Activations (Phenomenon) → Attention Sinks (Function) This suggests that it is precisely because those "Super Experts" generate extremely powerful signals (Massive Activations) that the model is able to form stable "focal points" (Attention Sinks), thereby processing information more effectively.
Impact of Pruning Super Experts on Attention Sinks: Loss of Focus
To validate this hypothesis, researchers measured a metric called "attention sink decay rate." This metric quantifies the degree to which "Attention Sinks" are disrupted after pruning "Super Experts".
The results indicate that after pruning "Super Experts", the "attention sink decay rate" for all layers of the model consistently stabilized at approximately 90%, and even approached 100%. This signifies that the removal of "Super Experts" severely disrupts the model's crucial internal attention mechanisms, preventing the model from forming effective "focal points."
We can visually observe this through the following charts: Attention Score Map of the Original Model
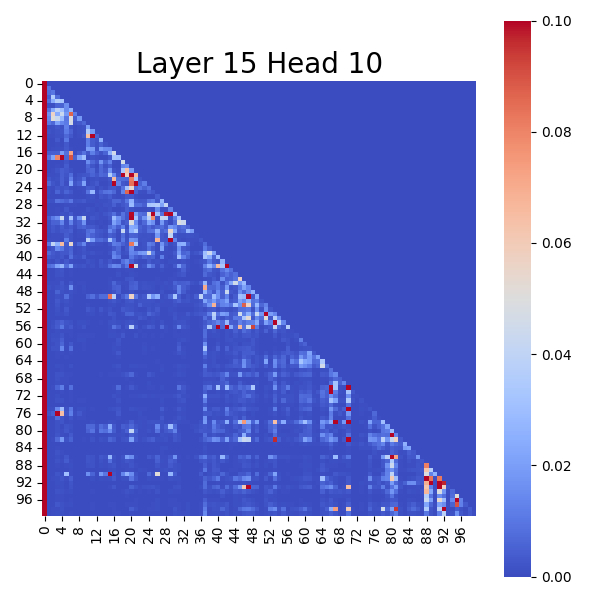
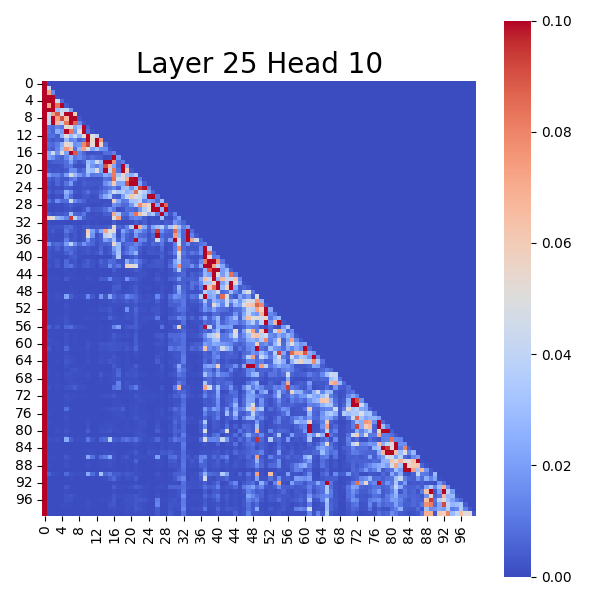
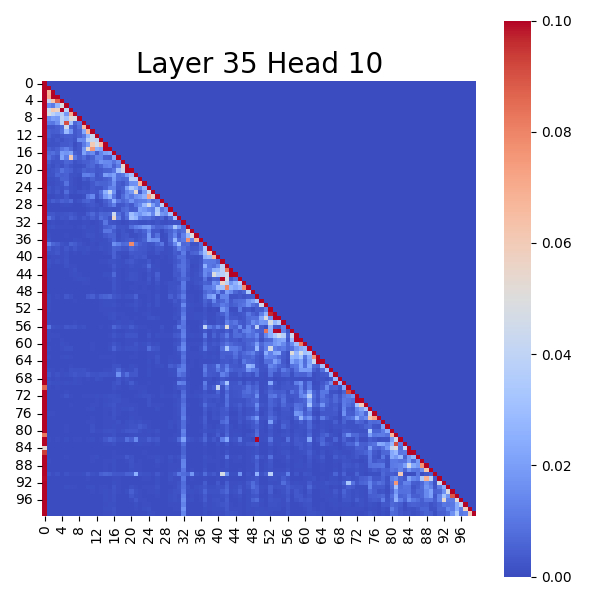
These charts show that in the original model, the top-left corner (typically the first token in a sequence) exhibits the deepest color, indicating the highest attention score, forming a clear "Attention Sinks".
Attention Score Map of Layer 15 Head 10 After Pruning Super Experts
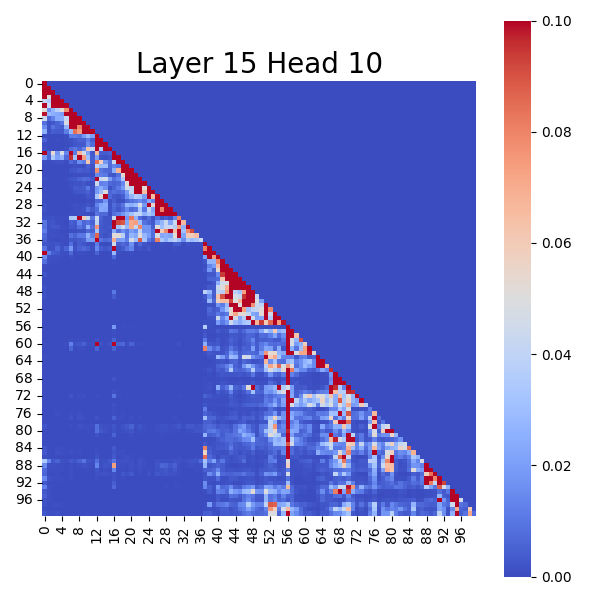
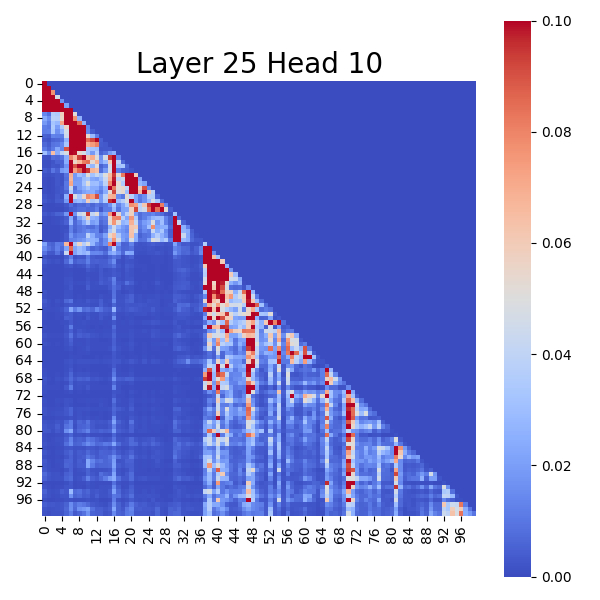
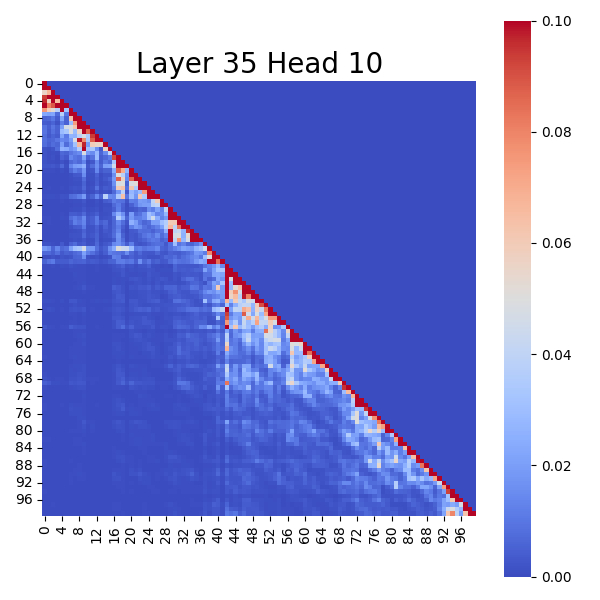
Conversely, after pruning "Super Experts", the "Attention Sinks" in these charts visibly disappear, and the color distribution becomes highly uniform. This intuitively demonstrates that the impact of "Super Experts" on attention computation is continuous and significant.
Research Contributions and Future Directions: Understanding and Optimization
This research primarily contributes in four key areas:
- First Identification and Systematic Analysis of "Super Experts": Their widespread existence in multiple mainstream MoE LLMs has been extensively validated, revealing the remarkable stability of their distribution, and an automated detection tool has been developed.
- Empirical Verification of "Super Experts'" Critical Role: Extensive experiments demonstrate their crucial importance to overall model capabilities, especially in mathematical reasoning tasks, with model performance almost "completely collapsing" after pruning.
- Revelation of the Impact of Pruning "Super Experts" on Attention Mechanisms: It confirms that MoE LLMs rely on "Super Experts" to form "Attention Sinks", and once pruned, this mechanism is severely disrupted, significantly weakening model performance.
- Providing New Directions for MoE LLM Compression Strategies: This discovery not only deepens our understanding of the internal behavior of MoE LLMs but also provides a theoretical basis for designing more robust and efficient model compression schemes in the future.
Future Research Directions:
- Explore how "Super Experts" are formed during the model's pre-training process.
- Leverage the characteristics of "Super Experts" to develop more efficient MoE LLM compression methods (e.g., perhaps by preserving or specially treating these "Super Experts" while more aggressively compressing other experts).
- Conduct more in-depth exploration of the previously mentioned "Outlier Experts".
Conclusion
In summary [...], this research is akin to discovering and proving the existence of a very small number of "key individuals" (Super Experts) within a vast, complex MoE LLM "company". These key individuals, by generating extremely powerful "signals" (Massive Activations), help the "company" form effective "focal points" (Attention Sinks), thereby ensuring its efficient operation in handling various tasks (especially complex reasoning tasks). If these key individuals are removed, the "company's" core capabilities will suffer severe damage, potentially even leading to a "short-circuited" thought process. This finding not only enhances our understanding of the internal workings of MoE LLMs but also points towards a more intelligent and efficient approach to "slimming down" these massive models in the future.



