Research Paper - MIT CSAIL - Beyond Context Limits - Subconscious Threads for Long-Horizon Reasoning - 突破上下文限制与提升长程推理效率:MIT CSAIL 团队的 TIM 与 TIMRUN 系统深度解析
What if the key to breaking an LLM's context limits lies not in remembering more, but in mastering the art of what to forget?

Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
Breaking Context Limits and Enhancing Long-Horizon Reasoning Efficiency: A Deep Dive into MIT CSAIL's TIM and TIMRUN Systems
Large Language Models have become an indispensable foundation in today's AI landscape, demonstrating remarkable capabilities, particularly in handling complex multi-hop reasoning and tool-use tasks. However, these models still face core challenges in practical applications: the very nature of their language modeling dictates that they generate unstructured token sequences linearly, which introduces inherent limitations such as strict context window constraints and difficulty in precisely controlling internal states. For instance, even models like Deepseek R1, boasting up to 128K tokens of input and output context, still encounter capacity boundaries when confronted with complex scenarios requiring more extensive long-horizon reasoning.
Traditional LLMs, whether Recurrent Neural Networks or Transformers, are constrained by token count, hidden state size, and GPU memory capacity. Although attempts exist to extend context, such as with Compressive Transformers, these methods often involve trade-offs between memory fidelity and computational efficiency. To circumvent these working memory bottlenecks, developers commonly adopt multi-agent architectures, decomposing complex workflows into multiple modules supported by independent model instances. However, this approach also introduces significant overhead: agents inherently lack control flow management or coordination, requiring developers to manually handle intricate context management, error handling, and inter-agent communication. Furthermore, integrating external tools adds another layer of complexity, as parameter generation, tool invocation, and response processing are often handled by disparate modules, increasing both development effort and runtime latency.
A collaborative team from MIT CSAIL, Subconscious Systems Technologies, Inc., and other institutions has proposed a groundbreaking solution in their latest research, aiming to overcome these inherent challenges of LLMs in long-horizon reasoning and efficiency. They posit that reasoning is not merely a linear process but a recursively structured one with intrinsic dependencies, much like language itself. This profound insight led them to develop the Thread Inference Model (TIM) and its dedicated inference runtime, TIMRUN. This system models the inference process as a recursively decomposable tree of subtasks, combined with innovative subtask pruning and efficient KV cache management mechanisms, enabling nearly infinite long-horizon reasoning and end-to-end multi-hop tool use that transcends the limitations of traditional LLMs.
Traditional Transformer models, during inference, need to attend to all reasoning tokens, causing context length to grow linearly with the number of tasks. This imposes a significant computational burden on models when processing long sequences.
Figure 1: Comparison of Information Compression in Traditional Transformers and Tree-Based TIM
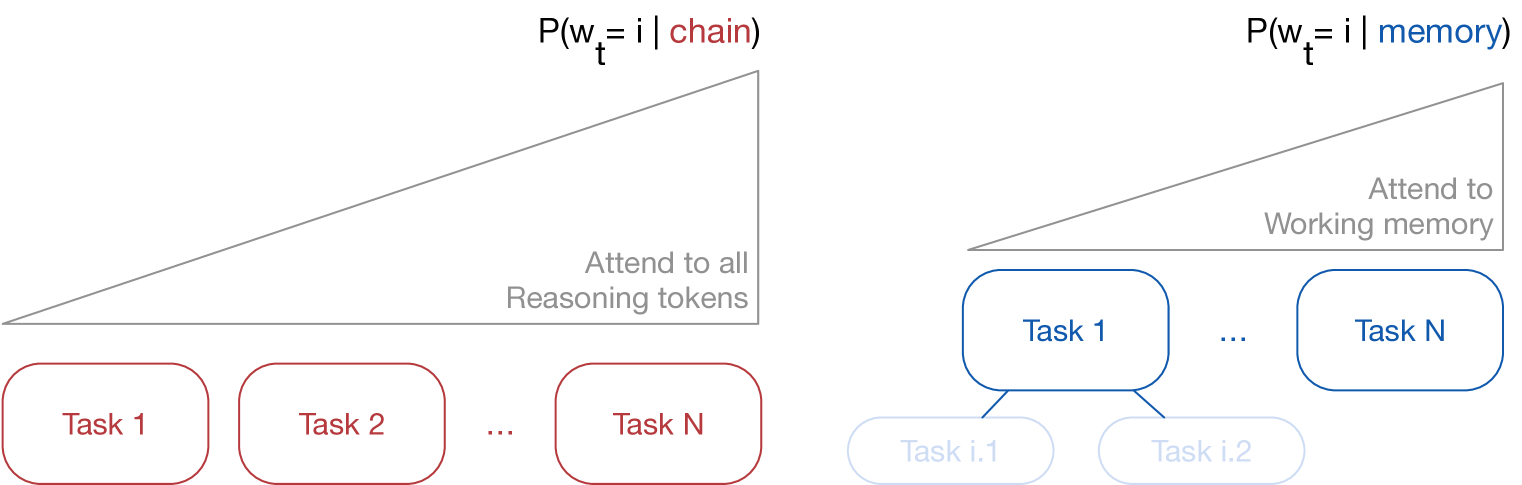
In stark contrast, the tree-based TIM achieves structured latent information compression by parsing the inference trajectory. It focuses solely on the KV states relevant to the current task, significantly reducing the computational load on the attention mechanism. By pruning irrelevant subtasks, TIM retains only a selective "working memory," thereby substantially cutting down on context tokens and KV cache entries during inference. This not only enables virtually unlimited long-horizon reasoning but also maintains awareness of instructions and crucial context, leading to higher decoding throughput and lower memory costs.
Core Design of TIM and Structured Inference
The Thread Inference Model, as a Transformer-based LLM, aims to learn and generate a recursive subtask tree structure. The fundamental unit of its inference is a "task," with each task comprising four key components:
thought: Contains the thinking process, used to capture errors from previous steps, analyze current progress, and plan subsequent actions.tooluse: Optional, invokes specific tools by generating tool inputs and encoding their responses upon reception.subtasks: Optional, generated if the current task requires multi-step reasoning. The inference details of these subtasks are hidden from the next step to enable efficient and concise context management.conclusion: Processes tool results, aggregates the conclusions of the current step's subtask list, and describes the current task's outcome. The conclusion contains sufficient information to support future inference tasks.
This framework, termed Thread-2, addresses the issue in the original Thread framework where high-level task instructions were not passed to subtasks, thus avoiding the redundancy of each subtask requiring a copy of the system message. Thread-2 allows subtasks to access a "working memory" containing system prompts, user inputs, and all unpruned tasks, ensuring that all necessary inputs are available to subtasks. This enables end-to-end inference, meaning the entire inference process can be completed with just a single LLM call.
To further reduce the complexity of the inference context, TIM introduces a "subtask pruning" mechanism. This rule-based approach eliminates the need for external summarization models or agent history memory. Its core idea is that when processing the current task, the model only needs to read the thoughts and conclusions of tasks at the same or higher hierarchical levels, while lower-level subtask lists can be safely ignored. In practice, pruning is achieved via a fixed-size subtask stack: when a subtask list is completed, it's added to the stack; if the stack size exceeds a preset threshold (typically 0, 1, or 2), the oldest subtask list is popped and pruned from working memory.
Thread-2's inference process can be efficiently decoded into JSON dictionaries, thanks to its "structured generation" capability. The research team leverages popular inference runtimes and constrained decoding engines, defining the recursive hierarchy and tool-use structure through a JSON schema.
Figure 2: JSON Schema Definition for Constrained Decoding
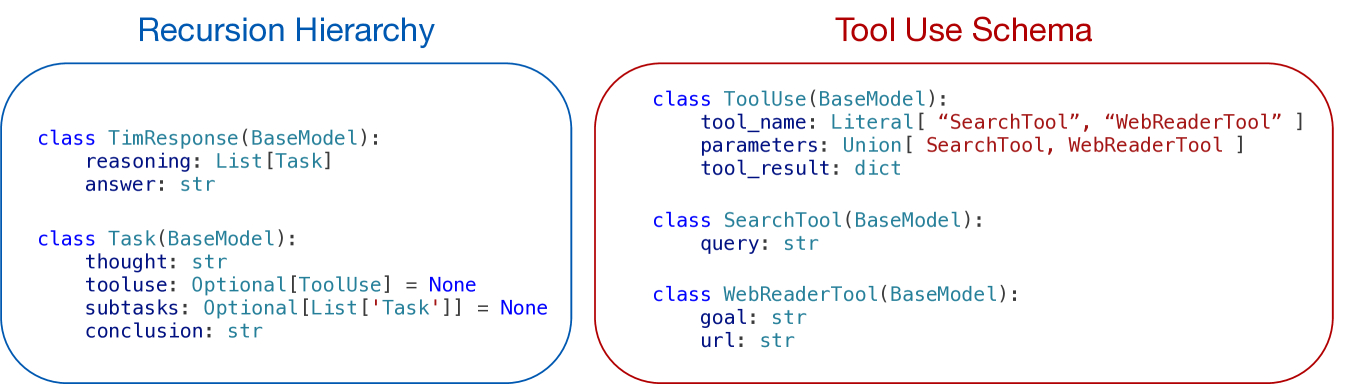
This mechanism allows a single decoding process to handle multiple tool calls, thereby avoiding the overhead associated with sending the entire message list multiple times in traditional message-list-based designs (e.g., state caching, network transmission, cache matching). In conventional methods, each tool call increases developer costs; for instance, a process requiring 20 tool calls might necessitate the developer paying 20 times for the initial input tokens. With TIM, during generation, when the tool_result keyword is output, parameters are extracted, and the system waits to receive tool responses as JSON dictionary strings, subsequently batch-encoding them to expand its KV cache. This enables the use of multiple tools via a single language model call, significantly reducing network latency and the overhead of multiple caching and retrieval operations.
For training, the research team fine-tuned a small open-source model (Qwen3-8b) using a small synthetic corpus as a proof of concept. Their primary goal was to demonstrate that subtask pruning does not impair inference accuracy and that intensive KV cache management does not introduce additional computational overhead. They created a synthetic training dataset comprising 20k openr1-math-220k problems, 20k research problems, and 6k ToolBench problems. The model was trained using supervised fine-tuning and reinforcement learning (with the GRPO algorithm), and results showed that reinforcement learning could enhance the performance of the fine-tuned model even with noisy and format-constrained datasets.
TIMRUN: The Dedicated Inference Runtime System for TIM
The structured output of TIM presents new opportunities for enhancing inference performance and accuracy but also introduces deployment challenges. To address this, the research team specifically designed the TIMRUN inference runtime system for the TIM model, aiming to fully leverage TIM's potential and resolve deployment obstacles.
A key distinction between TIM and traditional agents lies in their use of input and output windows: traditional agents incrementally update message lists and encode them into input sequences, whereas TIM executes the entire inference process within the output window. Since many language models have much stricter output window limits than input windows (e.g., Qwen 2.5 supports 128k input tokens but only 32k output tokens), TIMRUN must support GPU memory and positional embedding reuse to enable long-horizon inference.
The core of TIMRUN is its efficient "subtask pruning" mechanism, which is crucial for enabling TIM's long-term inference and maintaining efficiency. The central idea is that at any given moment, the model only needs the outputs of tasks at the same or higher abstract levels, and can safely discard the internal details of its subtasks. TIMRUN maintains a "pruning buffer," a temporary cache that stacks a small number of prunable subtasks, retaining enough redundancy to ensure lossless information flow.
Figure 3: Subtask Pruning Process Diagram
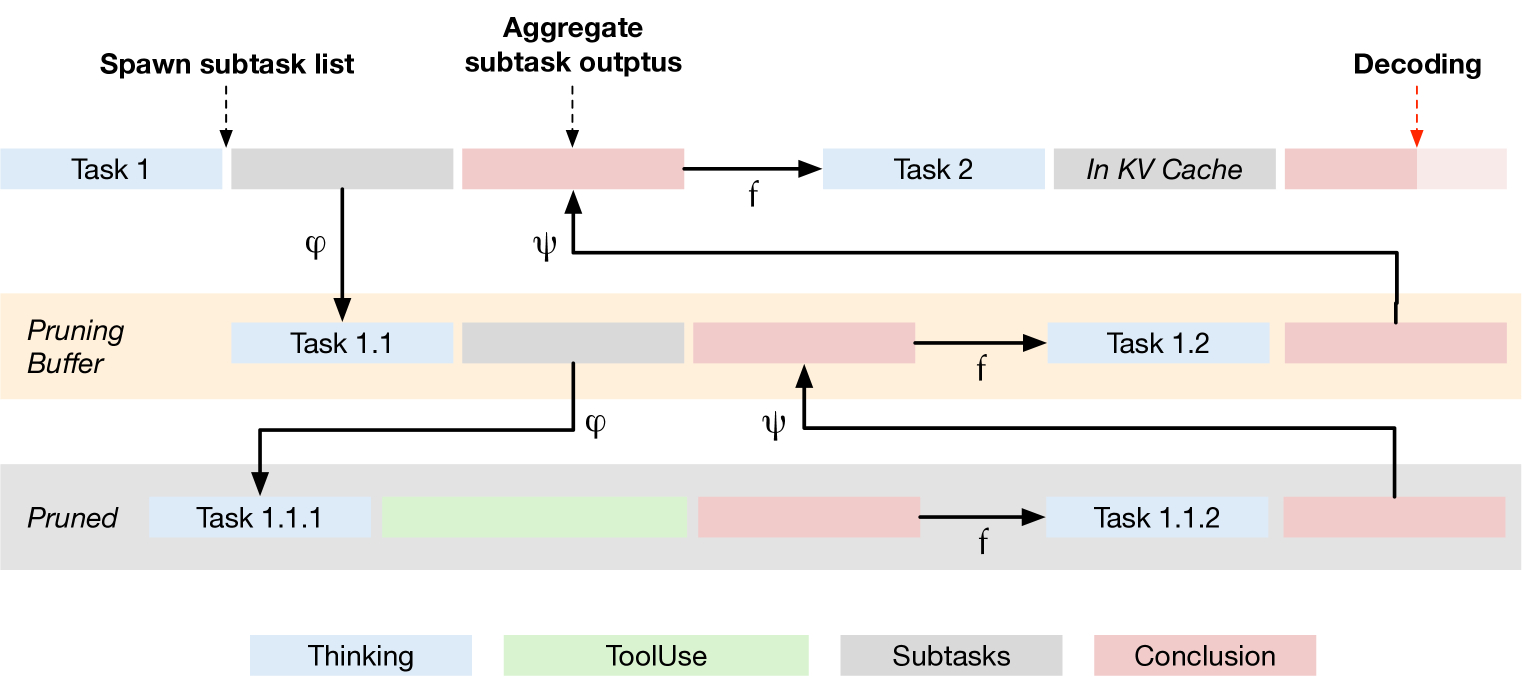
As shown in the diagram above, TIMRUN dynamically evicts KV states tokens belonging to completed subtasks from GPU memory during TIM's decoding tasks. To minimize the overhead of GPU memory management, TIMRUN uses paged-attention to process the KV cache and prune subtask tokens before inference. The dynamic subtask pruning mechanism sets the page size to 1 to accommodate the varying pruning needs of each request in a batch. Although the re-encoding process adds computational load, new tokens are encoded in parallel by GPU kernels, so the impact on overall throughput is minimal. Through proper subtask decomposition, TIM can iteratively reuse GPU memory and positional embeddings, enabling long-horizon inference beyond predefined output limits.
Furthermore, TIMRUN demonstrates significant advantages in "end-to-end multi-hop tool use." Traditional tool use and multi-agent frameworks often incur excessively high token costs due to repetitive prefilling. Conventional autoregressive Large Language Models generate in two stages: prefilling and decoding. With each new user interaction, the entire message list is sent to the LLM, leading to redundant transmission of most context, even if the inference engine caches the hidden states of previous tokens. Commercial LLM APIs typically charge for "encoded" cached tokens, causing developers to pay multiple times for the same tokens, even if they are not re-encoded. Tool responses are generated externally to the LLM service, and each tool call triggers re-encoding costs for all previous context tokens, significantly increasing expenses.
Figure 4: Comparison of Communication Methods: Traditional Inference Runtime vs. TIMRUN
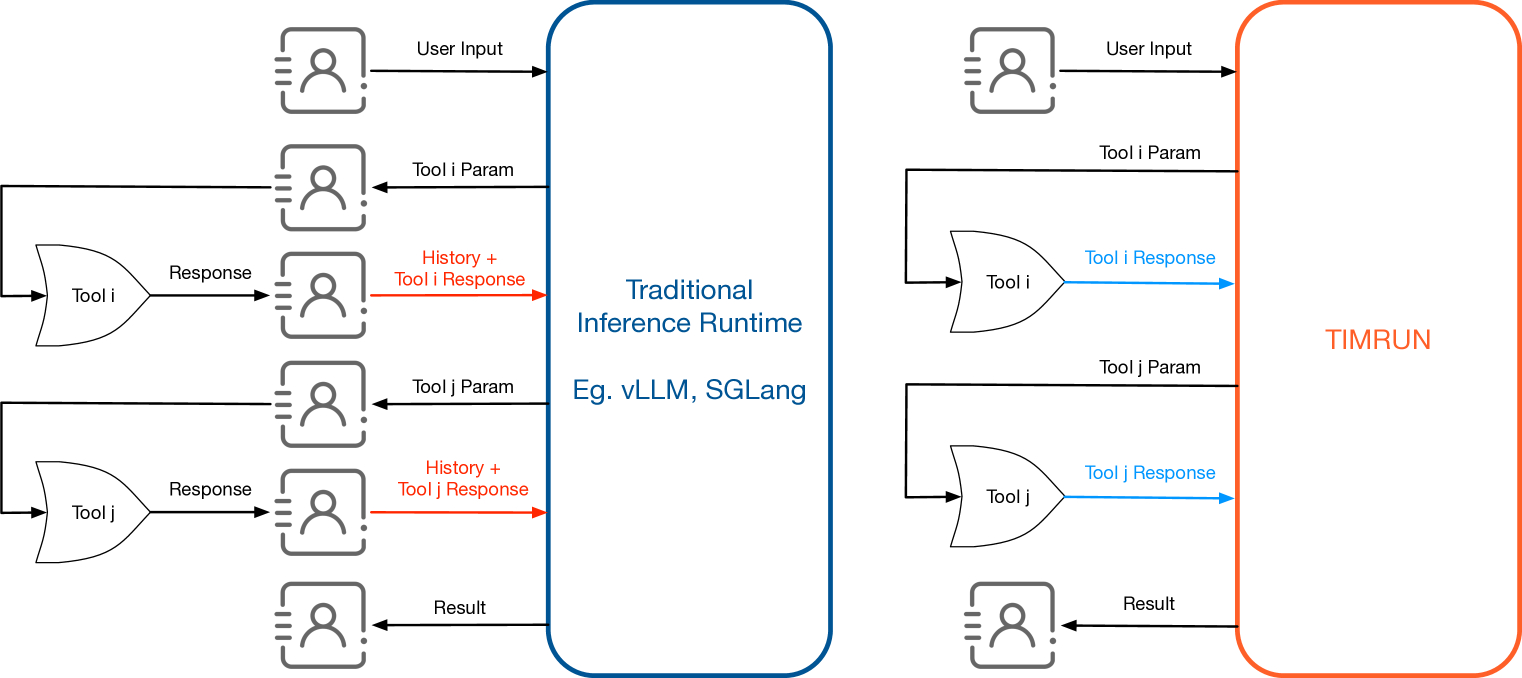
As depicted above, TIM's structured generation seamlessly integrates this process: when TIM outputs tool_result:, TIMRUN extracts the relevant parameters from the parameters: field, loads them as a JSON object, and forwards the request to the external tool. TIMRUN then appends the tool response to the ongoing inference process. Each token in the inference chain is transmitted to TIMRUN only once, eliminating redundant token transfers and minimizing communication overhead. This design also supports typical chatbot applications: after generating each response, TIMRUN initiates a tool call, passes the response to the user, and collects subsequent user input.
Experimental Results: Validation of Performance, Accuracy, and Efficiency
The research team validated the effectiveness of TIM and TIMRUN through a series of experiments, focusing on two main aspects: whether maintaining working memory impairs or even improves inference accuracy, and whether TIMRUN can sustain high throughput under intensive memory access and operations.
Inference Capability Validation
The research team evaluated TIM model's STEM knowledge and reasoning capabilities across several benchmarks, including MATH500, MMLU-STEM500, AMC 2022, AMC 2023, AIME 2024, and GPQADiamond. They compared TIM's performance on different service infrastructures: SGLang (which generates structured output but does not perform subtask pruning) and TIM + TIMRUN (which incorporates subtask pruning and memory management during decoding).
Table 1: Evaluation Results of TIM Model on Different Infrastructures
The experimental results clearly indicate that TIMRUN's subtask pruning mechanism did not reduce overall performance. Instead, by retaining only the most relevant information in the KV cache, the TIM model's performance improved on several tasks. Across all tested tasks, TIM not only achieved the reported performance but its peak KV cache length was typically less than half of what a full output sequence would require, representing significant memory savings.
Research Task Performance
Large Language Models combined with external knowledge typically require generating search queries for information retrieval, a process traditionally orchestrated by complex agent workflows. TIMRUN simplifies this by efficiently extracting tool parameters, invoking necessary tools, and directly appending raw tool responses to the output sequence, eliminating the need for developers to implement complex agent workflows.
In the Datacommons QA benchmark, the TIM model demonstrated exceptional performance when interacting with Datacommons. Compared to baseline methods that required lengthy task-specific prompts and examples, TIM achieved strong performance with only concise system messages and basic tool information.
Table 2: Performance of Different Methods on Datacommons QA Benchmark
Experimental results indicate that the TIM model exhibits strong generalization capabilities to new tasks not encountered during training, and offers significant efficiency advantages: it achieves robust performance without the need for elaborately designed few-shot examples and task-specific prompts; bypassing 4,000 token prompts significantly reduces computational overhead during generation; and developers no longer need to develop custom logic for tool response processing.
In Browsecomp, a challenging benchmark for deep research agents, TIM also achieved remarkable results. The research team generated a TIM-large model based on TIM's JSON design, validating the inference capabilities of TIM's new threading pipeline and its subtask pruning mechanism.
Table 3: Success Rate of LLMs in Browsing Across Different Paradigms
These results support the research team's hypothesis: a model capable of autonomously managing context through recursive subtask decomposition and working memory pruning can achieve performance comparable to more complex agent implementations. TIM-large significantly outperformed GPT-4o with browsing capabilities and achieved performance comparable to a ReACT agent based on Deepseek R1. Even the smaller TIM-8b model, when decomposing research tasks, outperformed GPT-4o in an end-to-end browsing setup.
Efficiency and Scalability
TIM's ability to dynamically prune subtasks and maintain working memory (with context tokens less than 50%) opens new possibilities for improving the throughput and memory efficiency of LLM service systems. Although theoretically, pruning the KV cache should reduce the computational cost of the attention mechanism, experiments showed that the overhead introduced by memory management actually led to a nearly 20% reduction in throughput when batch size was 1. This suggests that in practice, KV cache pruning's memory management might not be as efficient as directly computing attention on longer contexts.
However, TIMRUN can still effectively increase throughput despite the demands of structural checks and frequent memory access. In the AIME 2024 challenge, throughput was evaluated under different pruning buffer size configurations (batch size 30).
Figure 5(a): TIM Model Throughput Under Different Settings
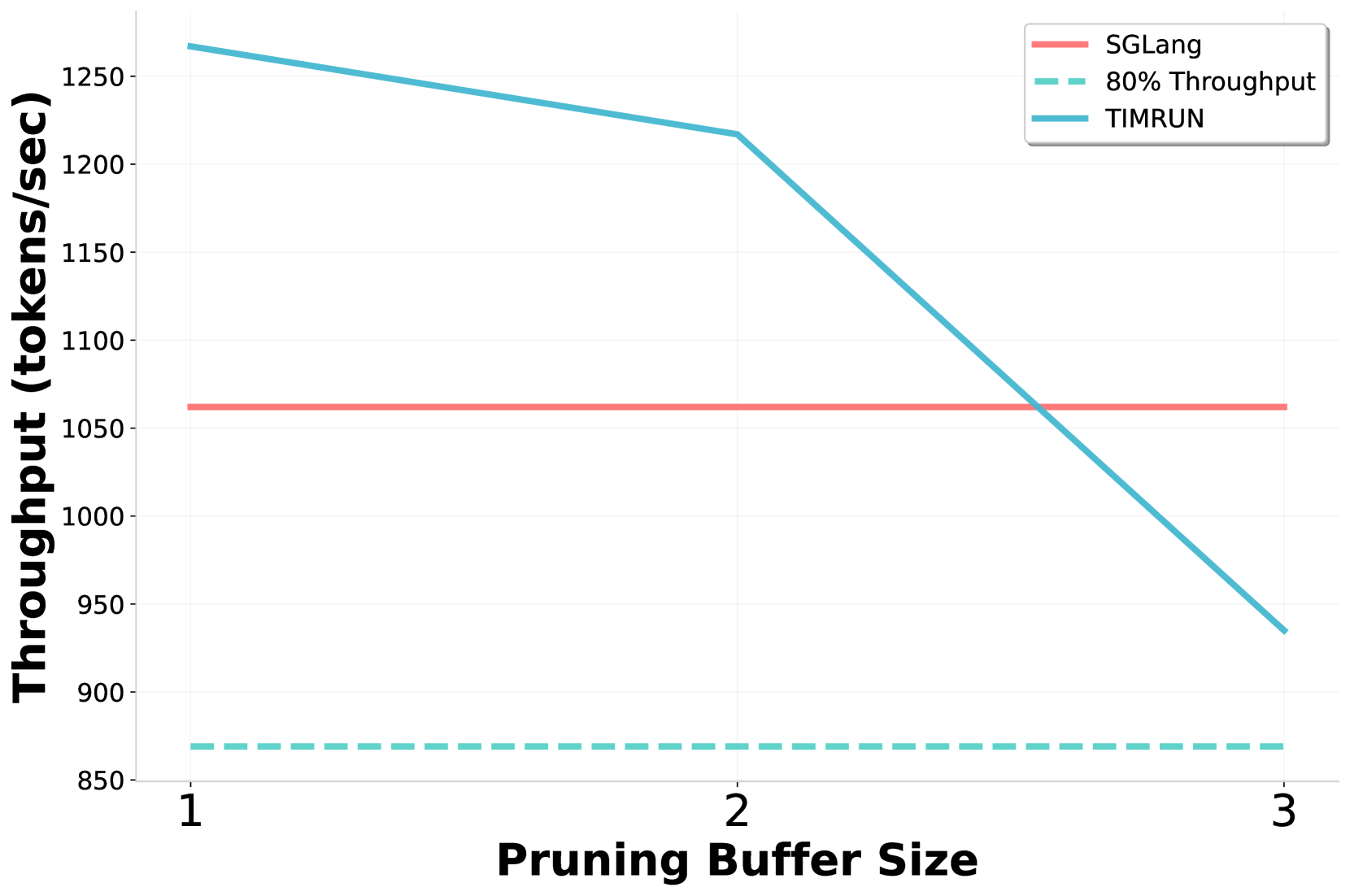
As shown above, TIMRUN achieved optimal throughput when the pruning buffer size was set to 2, while also balancing inference accuracy. In this configuration, the attention computation time saved by subtask pruning outweighed the additional memory access overhead, resulting in higher throughput than baseline systems. Overall, the TIMRUN system outperformed naive memory operations and the powerful SGLang baseline.
Regarding tool-use efficiency, TIMRUN can directly invoke custom tools from the runtime, bypassing the client or developer, which offers significant advantages in development simplicity and inference scalability. By invoking tools and encoding results directly within the runtime, TIMRUN avoids multiple overheads, including reduced network transmission latency and the elimination of the need to cache tokens and manage their associated states.
Figure 5(b): Throughput Comparison of TIM Model on SGLang and TIMRUN in Multi-Round Tool Use Tasks
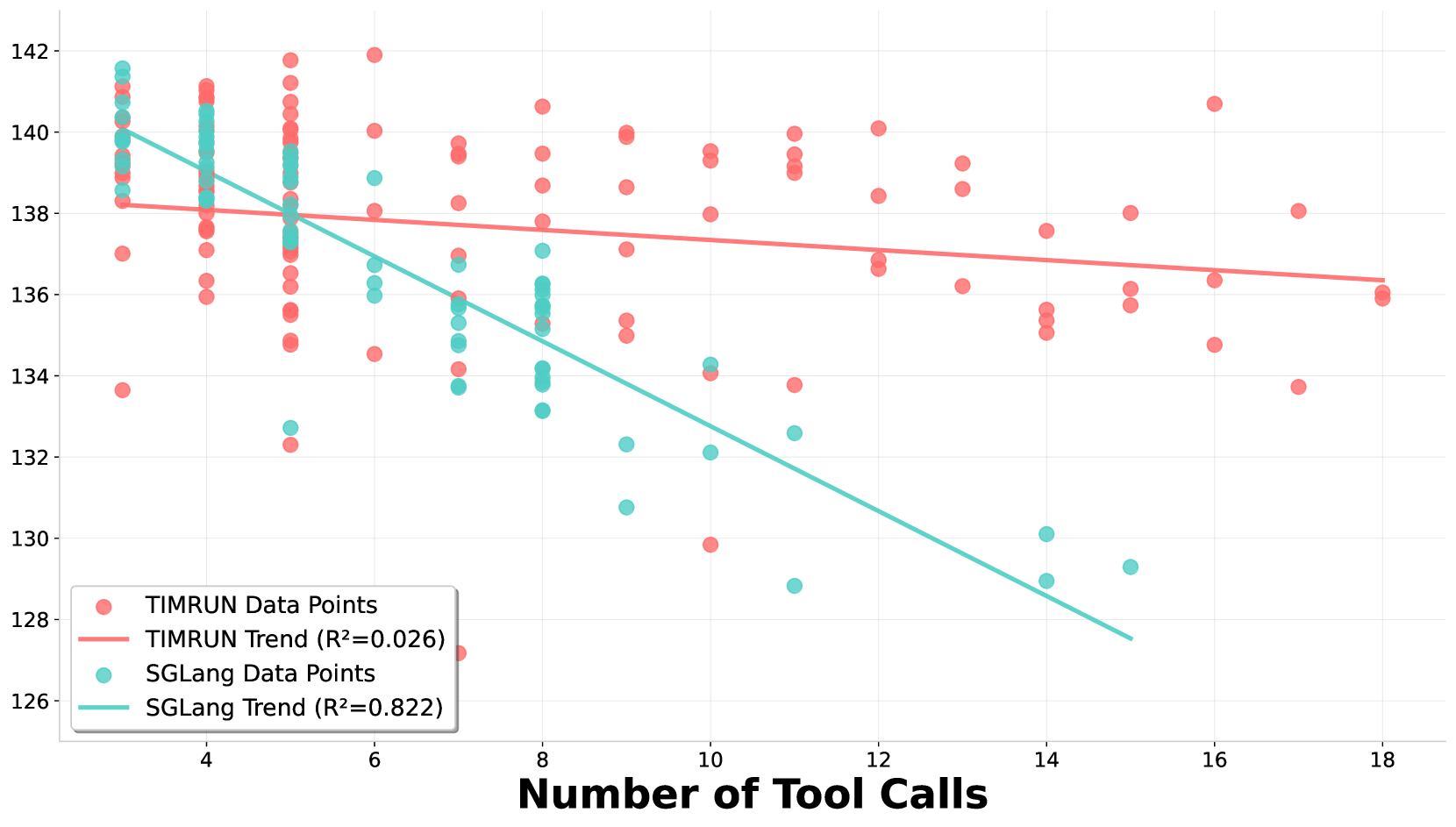
As illustrated above, SGLang's throughput rapidly declined with an increasing number of tool calls, reflecting the rising complexity of incremental context and token caching for inference steps and tool responses. In contrast, TIMRUN maintained relatively stable throughput even as tool use scaled, thanks to its automatic context management mechanism. This allowed the TIM-8b model to achieve strong performance in the BrowseComp benchmark without any agent framework or task-specific post-training. Through subtask pruning, TIMRUN even supported over 30 tool calls in a single inference.
Conclusion
The TIM and TIMRUN systems proposed by the MIT CSAIL team successfully overcome the limitations of traditional LLMs in long-horizon reasoning and efficiency by modeling the LLM inference process as a recursive subtask tree, combined with innovative subtask pruning and efficient KV cache management. Experimental results demonstrate that this co-designed system not only improves inference throughput and memory efficiency but also enhances performance on specific tasks by helping the model focus on relevant context. In agent benchmarks, TIM's performance matched that of powerful baselines relying on more complex agent frameworks and task-specific post-training, despite lacking explicit agent-specific design. The combination of TIM and TIMRUN provides powerful inference capabilities, more efficient reasoning and tool use, and greater flexibility and scalability in agent tasks, heralding new breakthroughs in LLM applications for complex task processing.



